
안드로이드와 Kotlin 독학하기 도전 중!
안드로이드 개발에서 비동기 동작을 위해 사용중인 Coroutine!
이 Coroutine에 대해서 공부하기 위해 인터넷 강의를 듣고 있던 중, Kotlin에도 Codelab(여기서는 Hands-On)이 있어
그 내용을 정리해보며 공부해보고자 이렇게 포스트를 적게 되었습니다. 😌
👇🏻 문서는 여기!
Coroutines and channels − tutorial | Kotlin
kotlinlang.org
1. 프로젝트 설치하기
안드로이드의 코드랩과 동일하게 핸즈온에서도 프로젝트 Repository를 제공해주고 있습니다.
이를 이용해 먼저 프로젝트를 PC에 설치해줄 필요가 있어요.
🌹 https://github.com/kotlin-hands-on/intro-coroutines.git
저는 folk를 뜨고 제 Repository에서 작업하였습니다.🤗
설치한 프로젝트를 실행하면 아래와 같은 Prompt가 띄워집니다.

2. Blocking requests
이번 핸즈온에서는 Retrofit 라이브러리를 사용해 서버로부터 데이터를 받아오는 기능을 예제로 들고 있습니다.
때문에 아래와 같이 Retrofit 코드도 프로젝트 내에 위치하고 있습니다.
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}먼저 getOrgReposCall을 통해서 Repository 리스트를 요청한 후,
각 Repository에 속한 Contributors 정보를 User 객체로 받아오는 서비스를 제공해줍니다.
Chapter2에서 중요하게 볼 곳은 바로 이러한 작업을 수행하는 loadContributorBlocking() 메서드 입니다.
🌹 src/tasks/Request1Blocking.kt 에서 찾을 수 있습니다.
위 파일을 못 찾겠다면 shift 키를 2번 눌러 파일을 검색하실 수 있습니다.👍🏻
Blocking은 여러 요청을 순차적으로 호출하는 방식입니다.

fun loadContributorsBlocking(service: GitHubService, req: RequestData) : List<User> {
val repos = service
.getOrgReposCall(req.org)
.execute() // Executes request and blocks the current thread
.also { logRepos(req, it) }
.body() ?: emptyList()
return repos.flatMap { repo ->
service
.getRepoContributorsCall(req.org, repo.name)
.execute() // Executes request and blocks the current thread
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}
위의 코드를 보시면 처음 getOrReposCall을 호출해 Repository 리스트를 받아오고,
각 Repository들을 가지고 다시 한번 더 getRepoContributorsCall 메서드를 호출하여 Contributors 정보를 받아오고 있습니다.
execute() 메서드를 호출하게되면 주석에도 적혀있듯이 결과를 받아올 때까지 해당 스레드는 block 되게 됩니다.
때문에 위 이미지처럼 contribs1이 완료된 이후에 contribs2를 요청하는 것처럼 순차적으로 작업을 수행하게 됩니다.
여기서 잠시! bodyList에 대해 알아보자
fun <T> Response<List<T>>.bodyList(): List<T> {
return body() ?: emptyList()
}loadContributorsBlocking 메서드와 동일한 파일 내에 정의되어 있는 Response<List<T>> 타입의 확장함수입니다.
그러면 Variant를 BLOCKING으로 멎추고 실행해보도록 하겠습니다.🤗

대략 28초의 시간이 지난 이후에 결과가 출력되는 것을 알 수 있습니다.
로그도 순차적으로 깔끔하게 찍히고 있죠.

하지만 실제 어플리케이션에서 만약 하나의 작업을 수행하는데 28초나 소요되었다면 사용자에게 좋은 UX를 제공하였다고 할 수 없습니다.😭
특히 안드로이드에서는 UI thread를 다른 작업이 오래 잡아두게 되면 ANR이 발생하여 앱이 종료될 수도 있는 치명적인 문제입니다.
2.1 Task1
aggregate() 메서드 구현하기
fun List<User>.aggregate(): List<User> {
return groupBy { it.login }
.map { (login, users) -> User(login, users.sumOf { it.contributions }) }
.sortedBy { it.contributions }
}
3. Callbacks
위에서 보았던 Blocking 코드의 문제점은
- UI 스레드를 잡아둔다.
- 순차적으로 작업이 수행되어 시간이 오래 소요된다.
1번 문제를 해결하기 위해서는 UI와 관련없는 연산을 다른 thread에서 수행하도록 한 뒤, 작업이 완료되면 callback 메서드를 호출하는 방법이 있습니다.
callback은 특정 작업이 완료된 이후에 호출되는 함수이며, 주로 람다로 전달되기 됩니다.
위에서 사용한 loadContributorsBlocking 메서드를 다른 thread에서 호출해보도록 하겠습니다.
fun loadContributorsBackground(
service: GitHubService,
req: RequestData,
updateResults: (List<User>) -> Unit
) {
thread {
val result = loadContributorsBlocking(service, req)
updateResults(result)
}
}요렇게!하면 loadContributorsBlocking의 모든 작업을 다른 thread에서 수행하게 됩니다.

thread(T1) 내에서 loadContributorsBlocking 작업이 완료된 이후에 UI를 업데이트 해줄 수 있도록
updateResults callback 메서드를 호출해주는 것을 잊으면 안 됩니다.
thread 메서드는..
val thread = object : Thread() {
public override fun run() {
block()
}
}내부적으로 Thread를 생성해 전달된 block을 호출해줍니다.
이제 다른 작업에 의해 UI thread가 Blocking 되지 않도록 하였습니다.
하지만 아직 Contributors를 받아오는 작업을 순차적으로 수행하는 것이 신경쓰입니다. 🤔
3.1 Retrofit callback API
서버 요청을 순차적이 아닌 병렬적으로 수행하기 위해 Retrofit의 callback API인 Call.enqueue()를 사용할 수 있습니다.

fun loadContributorsCallbacks(
service: GitHubService,
req: RequestData,
updateResults: (List<User>) -> Unit
) {
val counter = AtomicInteger()
service.getOrgReposCall(req.org).onResponse { responseRepos ->
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name).onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (counter.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}
}
}
여기서 onResponse는 동일한 파일에 정의되어 있는 확장함수입니다.
inline fun <T> Call<T>.onResponse(crossinline callback: (Response<T>) -> Unit) {
enqueue(object : Callback<T> {
override fun onResponse(call: Call<T>, response: Response<T>) {
callback(response)
}
override fun onFailure(call: Call<T>, t: Throwable) {
log.error("Call failed", t)
}
})
}
enqueue를 통해 성공적으로 완료되었을 경우 callback parameter로 전달된 메서드를 호출하는 것을 알 수 있습니다.
이를 통해 여러 요청들을 비동기적으로 호출한 후 결과값을 반영할 수 있습니다. 🤗👍🏻
하지만 callback메서드를 사용할 경우 가독성에 큰 악영향을 끼칠 수 있습니다.
바로 callback hell이죠. 😱
4. suspend function
이를 위해 callback 대신 suspend function을 사용해 callback 대신 일반 함수를 호출하는 것처럼 코드를 작성해보도록 하겠습니다.
먼저 GitHubService 인터페이스의 코드를 수정해주세요.
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}
suspend를 사용하기 때문에 수행중이었던 thread는 Blocking되지 않습니다.
또한 반환값으로 Call 대신 List<Repo>를 직접 반환하고 있습니다.
그러나 직접 결과값을 반환할 때는 서버 요청에 실패할 경우, Exception이 던져집니다.
이러한 문제를 피하기 위해 Retrofit에서 제공해주는 Response를 반환하도록 수정하겠습니다.
이 Response를 통해서 결과값을 받거나 직접 에러를 처리할 수도 있습니다.
👇🏻 요렇게!
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgReposCall(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}
이렇게 suspend를 사용하게 되면 호출하는 부분을 간단하게 구현할 수 있게 됩니다.
suspend fun loadContributorsSuspend(
service: GitHubService,
req: RequestData
): List<User> {
val repos = service
.getOrgReposCall(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributorsCall(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}
getOrgReposCall과 getRepoContributorsCall이 suspend Function이기 때문에 loadContributorsSuspend도 suspend Function으로 정의해주어야 함에 유의하세요.🤗
아직 위 코드가 완성된 것은 아닙니다!
저희는 getRepoContributorsCall이 비동기적으로 호출되길 원하죠. 이를 위해 각 호출마다 새로운 코루틴을 생성해줄 필요가 있습니다.🔥
👇🏻 현재는 아래와 같이 동작
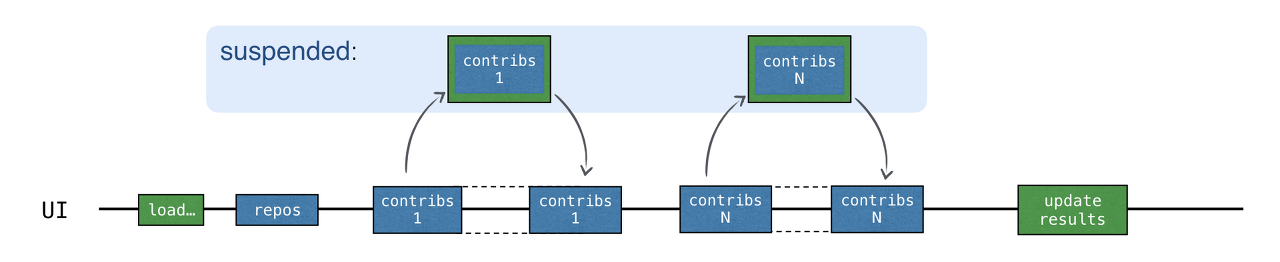
새로운 코루틴을 생성하기 위해서는 launch, async, runBlocking과 같은 코루틴 빌더를 사용합니다.
이중 async는 새로운 코루틴을 생성하면서 Deferred 객체를 반환하게 됩니다.
🌹 Deferred 객체를 통해 비동기적으로 수행된 연산의 결과값을 받아올 수 있습니다.
하지만 launch는 동일하게 새로운 코루틴을 생성하지만 값을 반환하지 않을 때 사용될 수 있습니다.
launch 코루틴 빌더는 Job 객체를 반환하게 되는데, 이를 통해 코루틴들을 제어(관리?)할 수 있습니다.
// Deferred도 Job의 하위 인터페이스
public interface Deferred<out T> : Job
📌 runBlocking도 알고가자!
runBlocking은 일반 함수와 suspend function를 연결해주는 역할을 담당하며,
주로 main() function과 테스트 같이 main 코루틴 최상위에서 코루틴을 생성해줄 때 사용됩니다.
자! 다시 돌아와서 최종적인 목표였던 getRepoContributorsCall을 비동기적으로 호출해보도록 하겠습니다.
위에서 말했던 여러 코루틴 빌더 중에 저는 반환값이 필요하므로 async를 사용해보았습니다.
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
val repos = service
.getOrgReposCall(req.org)
.also { logRepos(req, it) }
.bodyList()
// coroutinescope는 마지막 값이 반환값!
repos.map { repo ->
async {
service.getRepoContributorsCall(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
}.awaitAll().flatten().aggregate()
}
위 코드는 아래 이미지와 같이 각 contributors 요청을 비동기적으로 수행하게 됩니다.

모든 작업을 수행하는데 걸린 시간도 엄청 줄어든 것을 볼 수 있습니다.(크으..👍🏻)

수행 결과만 보면 callback을 사용했을 때와 크게 다르지 않지만!
코드가 훨씬 더 깔끔해진 것을 알 수 있습니다. 👍🏻👍🏻👍🏻
하지만 여기서 하나 더 수정하고자 하는 것이 있습니다.
로그를 확인해보면 모든 코루틴 작업이 하나의 스레드에서 수행됩니다.

여러 스레드에서 동작할 수 있도록 다른 Dispatcher를 async의 인자로 전달할 수 있습니다.
👇🏻 요렇게
async(Dispatchers.Default) {
service.getRepoContributorsCall(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}하면 아래와 같이 여러 worker에서 작업이 수행되게 됩니다.

📌 여기서 잠깐! Dispatcher.Default는 몇 개의 thread를 가지고 있을까? 🤔
Dispatcher.Default는 연산을 수행하는 코루틴으로 CPU 코어의 개수만큼 thread가 존재합니다.
만약.. 코어가 하나밖에 없는 기기라면! 이라도 2개의 thread가 존재하게 됩니다.
추가적으로!
만약 getRepoContributorsCall이 아닌, loadContributorsConcurrent 메서드 자체를 Dispatchers,Default에서 호출할 수도 있지 않을까?
// 이걸
launch {
val users = loadContributorsConcurrent(service, req)
updateResults(users, startTime)
}.setUpCancellation()
// 이렇게
launch(Dispatchers.Default) {
val users = loadContributorsConcurrent(service, req)
withContext(Dispatchers.Main) {
updateResults(users, startTime)
}
}.setUpCancellation()
물론 정상적으로 동작은 합니다.
🌹이 때 주의할 점! UI를 변경하는 updateResult는 반드시 UI 스레드인 Main 스레드에서 수행이 되어야 합니다.
때문에 withContext(Dispatchers.Main)을 반!드!시! 추가해주어야 합니다.
📌 withContext
특정 코루틴 Context에서 주어진 코드를 실행하고나서 결과값을 받고자 할 때 사용할 수 있는 suspend function입니다.
suspend function이기 때문에 launch(context) { ... }.join()과 동일하게 결과값을 반환할 때까지 기다리게(wait) 됩니다.
뭔가 기능이 async와 동일해보이지만, async는 suspend function이 아니고 await을 통해서 결과값을 받을 수 있습니다.
5. 구조적인 동시성(Structured concurrency)
Coroutine Scope
- 코루틴의 구조와 서로 다른 코루틴들 간의 부모-자식 관계를 나타내는 인터페이스입니다.
- 내부적으로 Coroutine Context를 가지고 있으며, 자식 코루틴 스코프는 이 Coroutine Context를 상속받게 됩니다.
- 이렇게 상속된 Coroutine Context를 통해 부모에서 자식으로 필요한 정보나 취소가 자동으로 전파되게 됩니다.
- launch / async / runBlocking을 통해 새로운 Coroutine Scope가 생성되며, 전달된 람다의 수신객체는 CoroutineScope입니다.
🌹 코루틴 빌더(launch, async)들은 CoroutineScope의 확장함수이며, runBlocking은 top-level 함수에서 non-blocking 영역과 blocking 영역을 연결하는데 사용되므로 CoroutineScope의 확장함수는 아닙니다.
- 이러한 부모-자식 관계로 이루어져 있기 때문에 자식 코루틴이 모두 종료될 때까지 부모 코루틴은 살아있으며, 부모 코루틴이 종료되면 모든 자식 코루틴 또한 종료됩니다.
📌 추가적으로! 핸즈온을 진행하면서 헷갈리는 coroutineScope { }, withContext() { }, MainScope()에 대해 알아보자!
1. coroutineScope()
suspend fun <R> coroutineScope(block: suspend CoroutineScope.() -> R): Rsuspend에 값을 반환하지만, 실행될 Coroutine Context를 직접 지정할 수 없고, 부모로부터 상속받아 사용합니다.
2. withContext()
suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): Tsuspend에 값을 반환하면서 실행된 CoroutineContext를 직접 지정할 수 있다.
3. MainScope()
위 두 메서드와 달리 CoroutineScope만을 생성하는 함수입니다. 🤗
fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)
Coroutine Context
- 코루틴이 동작하는데 필요한 정보를 가지고 있는 인터페이스입니다.
- Dispatcher, 코루틴 이름 등이 포함되어 있습니다.
- CoroutineContext.Element 구현체들을 조합해서 Context를 생성할 수 있습니다.
예를 들어, 해당 코루틴이 Supervisor Job이면서 IO 스레드에서 동작하고자 한다면
launch(SupervisorJob() + Dispatchers.IO) { }요렇게 작성할 수 있다. 마치 레고 조각들을 조립해서 원하는 동작을 수행하는 기계를 만드는 것과 비슷해 보인다. 😆
이 때, Job을 미리 만들어두고 Coroutine Context를 만드는데 사용한다면, 해당 Job을 가지고도 Coroutine을 제어할 수 있습니다. 👍🏻
fun main() = runBlocking {
val job = Job()
launch(job) {
loadData()
}
println("waiting...")
delay(2000)
job.cancelAndJoin()
}
GlobalScope
🌹 이름 그대로 전역적인 Coroutine Scope이며, 어플리케이션이 죽을 때까지 쭉 살아있는 Scope입니다.
즉, 해당 Scope 내에서 수행중인 작업은 어플리케이션 자체가 종료될 때까지 계속해서 수행된다는 의미이며,
Activity 또는 Fragemtn가 종료되어도 계속 수행되어야 하는 작업(ex. DB 저장, 서버로 데이터 전송)이 있다면
해당 GlobalScope 내에서 수행할 수 있습니다.
6. App에 Progress 추가하기
지금까지 Coroutine의 기본에 대해서 공부해 보았습니다.
이번에는 Progress를 추가해보면서 Channel에 대해 학습해보겠습니다. 🤗
프로젝트 패키지 src/tasks/Request6Progress.kt
처음은 가장 간단하게! 동기/비동기 상관없이 코드를 구현해보겠습니다.

6.1 Task6
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgReposCall(req.org)
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributorsCall(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}
위처럼 순차적으로 동작하는 코드를

이렇게 동작하도록 하기 위해 바로 Channel을 사용해보겠습니다. 🔥
7. Channels
드디어 마지막 Chapter인 Channel 입니다.
Coroutine들끼리 통신을 할 때 사용되는 것이 바로 Channel입니다.
데이터를 생산하고 보내주는 producer와 producer가 보내준 데이터를 받아서 사용하는 consumer로 구성되어 있습니다.

위와 같이 깔끔하게 하나의 producer와 하나의 consumer 사이에서 통신이 이루어질 수도 있지만,
아래와 같이 여러 producer와 여러 consumer가 하나의 채널을 공유할 수도 있습니다.

이 때 주의할 점은 한번 소비된 데이터는 다시 발생되지 않으므로,
만약 consumer #1이 A라는 데이터를 받아 사용하였다면, consumer #2는 이 데이터를 사용할 수 없습니다.
채널에는 기본적으로 send와 receive Function이 제공됩니다.
이 둘은 모두 suspend function이며, 기본적으로(default) send는 consumer가 receive할 때까지, receive는 반대로 producer가 send할 때까지 suspend되게 됩니다.
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
위 코드에서 알 수 있듯이 Channel은
- SendChannel: 오직 데이터를 보낼(send) 수 있는 Channel
- ReceiveChannel: 오직 데이터를 받을(receive) 수 있는 Channel
를 구현하고 있습니다.
7.1 Channel의 종류
buffer의 크기에 따라 Channel의 종류를 나눌 수 있습니다.
send는 이 buffer가 가득 찰 때까지 데이터를 보낼 수 있으며, recevie는 해당 buffer에서 데이터를 가져와 작업을 수행합니다.
🌹 buffer가 가득찼을 때 수행하는 동작도 개발자가 지정할 수 있습니다.
기본적으로는(default) suspend 됩니다.
7.1.1 Rendezvous Channel(랑데뷰 채널)
val rendenzvousChannel = Channel<String>()- buffer 없이 동작하는 채널로, Default 채널입니다.
- buffer가 없기 때문에 send와 receive는 상대가 호출되어 데이터를 보내거나 받을 때까지 suspend 됩니다.

7.1.2 Buffered Channel
val bufferedChannel = Channel<String>(10)- 전달된 size 인자만큼의 buffer를 생성하며, Producer는 buffer가 가득찰 때까지 데이터를 전송할 수 있습니다.
- buffer가 가득차게 된다면, suspend 됩니다.
7.1.3 Conflated Channel
val conflatedChannel = Channel<String>(CONFLATED)- Producer는 계속해서 send를 할 수 있지만, 만약 buffer가 가득차게 된다면 가장 오래된 데이터를 지우고 새로운 데이터를 추가하게 됩니다.

7.1.4 Unlimited Channel
- 이름 그대로 buffer의 크기에 제한이 없는(Unlimited) Channel입니다. ( 사실 Int.MAX_VALUE )
- 동작은 Buffered Channel과 동일합니다.

그러면 이러한 Channel을 사용해 이전에 보았던 Progress 코드를 개선해보도록 하겠습니다.
Task7
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgReposCall(req.org)
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributorsCall(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}
지금까지 kotlin 공식문서를 보며 Coroutine과 Channel 기본에 대해서 학습해보았습니다. 😭
공부할 건 너무 많고 시간은 한정되어 있네요.
다음은 또 다른 주제에 대해서 학습하면서 내용을 정리해보도록 하겠습니다. 🔥
감사합니다. 😌
'Kotlin' 카테고리의 다른 글
| data object! (1) | 2024.11.09 |
|---|---|
| [Coroutine] 코루틴 내부동작 분석해보기! (0) | 2023.03.27 |
| [Flow] 연산자 내부코드를 열어보자! (0) | 2023.01.28 |
| [Equality] == vs. === (0) | 2023.01.28 |
| [Kotlin] use (0) | 2022.05.14 |